
Distributed Heterogeneous Restricted Boltzmann Machines for Book Recommendation
Research Motivation
- Today, the number of contents available around the world and the number of users is exploding
- It takes a lot of time and effort for users to find the content they want
-
Recommendation systems can help users overcome these challenges and provide practical search services
By utilizing multiple RBMs(Restricted Boltzmann Machines) together, we wished to build a more robust recommendation system that can account to various user traits
Suggested Model
Distributed Heterogeneous Restricted Boltzmann Machines for Book Recommendation
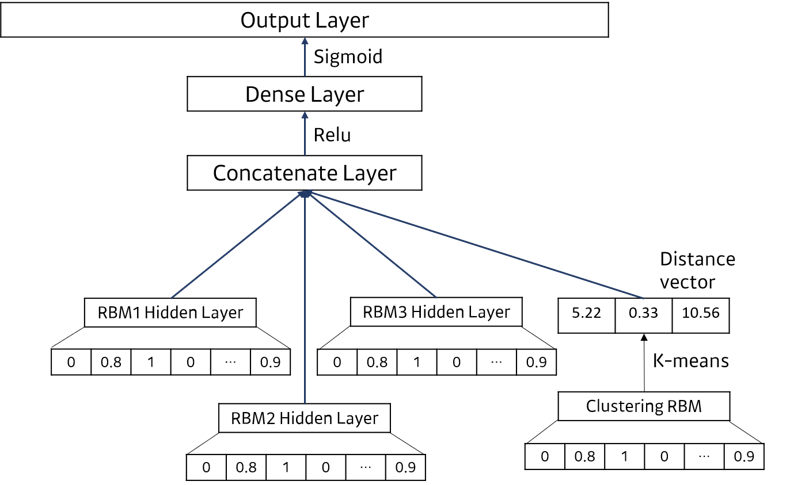
- Train M x N size data with RBM (M: Number of Users, N: Number of Items)
- Obtain latent feature of each user from RBM’s hidden vector
- Using the latent features from ②, cluster users to 3 groups with K-means clustering algorithm
-
Additionally train the pretrained RBM with the data of each group → obtain 3 heterogeneous RBMs specialized to each group
Using the 3 heterogeneous RBMs, ensemble the outputs to provide more personalized recommendation to users
Experimentation Data
- Used web-crawled review data from an online bookstore(Aladdin)
- Crawled reviews of 12,000 books and filtered out users and books with less than 2 reviews
-
Finally, used a total of 6,000 books and 4,500 users’ review data
Users Items Ratings Rating density 4,542 5,992 55,019 0.20%
Comparison of Different Ensemble Methods of Heterogeneous RBM outputs

M-Selection: Use only the output of the RBM trained on the cluster to which the input user belongsM-Weighted: Use the weighted average of each RBM output with the distance between the hidden vector of the input user and the K-means centroids.-
M-Ensemble: Using MLP, gather RBM’s hidden vectors to create an ensemble network that predicts scores for each itemM-Selection M-Weighted M-Ensemble HR@10 0.05947 0.06278 0.07489 HR@25 0.1200 0.1167 0.1233 ARHR 0.003786 0.003541 0.004342 Time(sec) 1.0300 1.0040 0.5230 The experiment result shows that the M-Ensemble method performs better than the other two methods.
Comparison to Baseline Recommendation Methods

M-Ensemble: Proposed modelItempop: Recommend the most popular itemsItempop-Cluster: Recommend the most popular items from the cluster the input user belongs toSVD: Collaborative Filtering method using SVD Matrix Factorization-
NMF: Collaborative Filtering method using NMF Matrix FactorizationM-Ensemble ItemPop ItemPop-Cluster SVD NMF HR@10 0.07449 0.01872 0.02093 0.05617 0.01432 HR@25 0.1233 0.03524 0.04295 0.1090 0.03414 ARHR 0.004342 0.0007325 0.001186 0.003223 0.0008671 Time(sec) 0.6060 0.08100 0.8650 7.176 11.43 The experiment result shows that the proposed model has a higher recommendation performance in a relatively small amount of time.
Comparison to Single RBM Model

M-Ensemble: Proposed modelControl-256: RBM with latent dimension of 256Control-512: RBM with latent dimension of 512-
Control-1024: RBM with latent dimension of 1024M-Ensemble Control-256 Control-512 Control-1024 HR@10 0.07449 0.06278 0.05507 0.04956 HR@25 0.1233 0.1178 0.1167 0.1123 ARHR 0.004342 0.003378 0.004011 0.004243 Time(sec) 0.6060 0.2290 0.3210 0.4900 The experiment result shows that the performance of multiple RBMs is higher than that of a single RBM.
Conclusion
Conclusion
- Improved the recommendation performance of RBM based Collaborative Filtering system by designing a distributed ensemble structure using multiple RBMs
- The distributed structure can be used in a distributed computing environment to save training and prediction time
Future Work
- Analyzing recommendation performance in different domains other than book recommendations to see if the proposed system can be applied to other domains as well
- Conduct experiments in which other recommended models such as an Autoencoder are applied instead of RBM to see if the distributed structure applies to other models as well